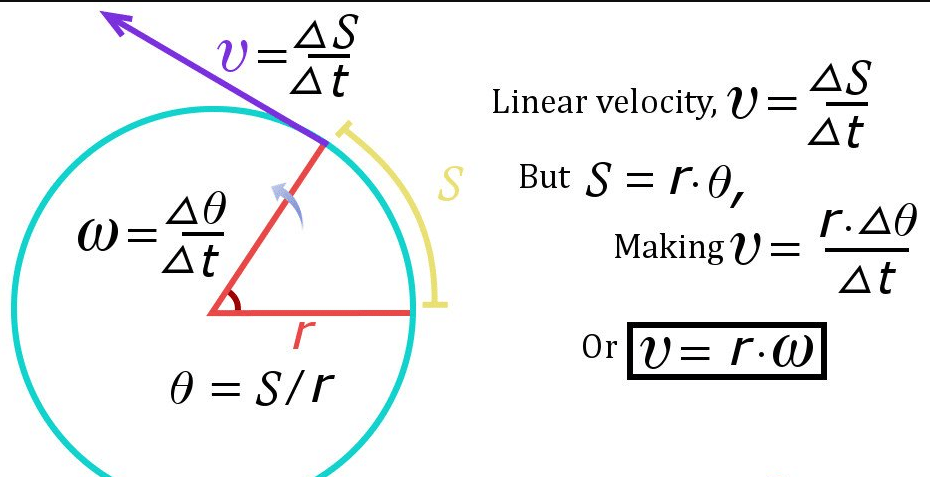
How to Calculate Tangential Velocity
The Steps Did you recognize that while you trip your bicycle, your bicycle honestly is visiting at one of a kind speeds? One pace is your tangential speed, your pace going ahead and the opposite is your angular speed, the …

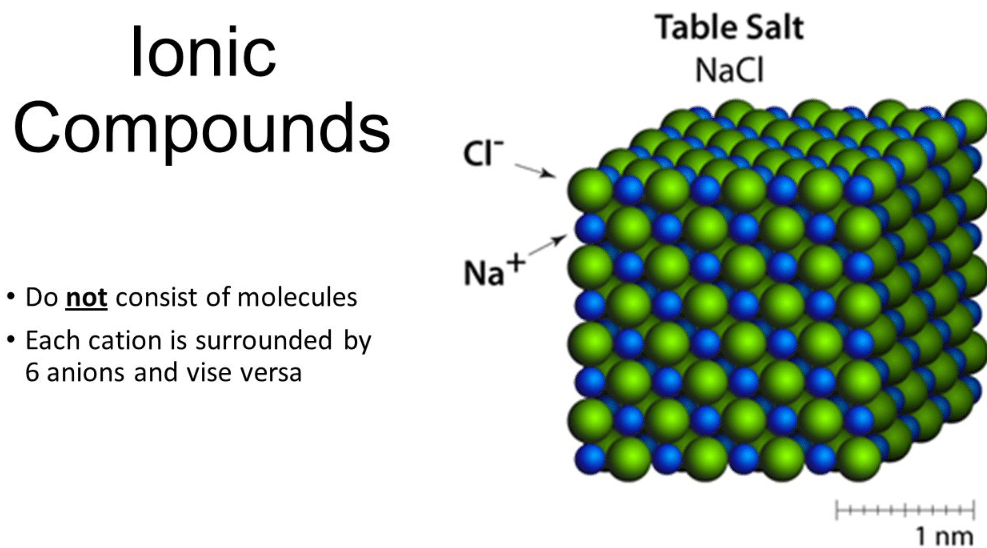
What is Ionic Compound?
In different words, ionic compounds held collectively via way of means of ionic bonds as classed as ionic compounds. Elements can benefit or lose electrons to be able to acquire their nearest noble gas configuration. Formation of ions (both via way of …


Abyssal Zone: Definition & Examples
What is the Abyssal Zone? Picture the private, darkest a part of the sea. Fish that glow within side the darkish, giant sea worms, and explosive, hydrothermal vents. This creepy scene is the abyssal region. Additionally, the abyssal …

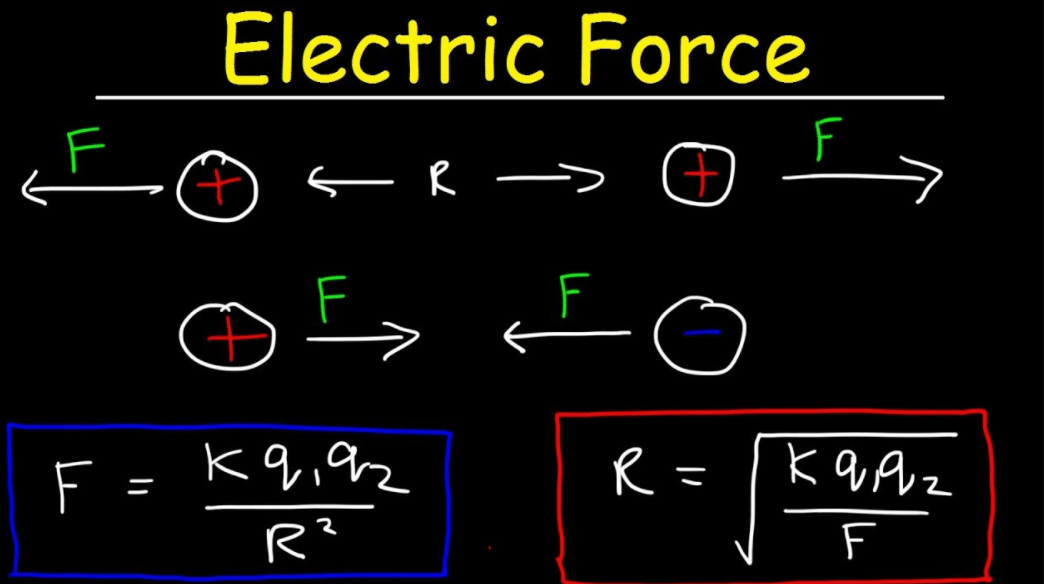
Electric Force: Definition & Equation
What is Electric Force? Force is a phrase this is utilized in regular language to intend many special things, however in physics, it has a totally unique meaning. In physics, a pressure is an interplay among items that has the …


What Are The Five Themes of Geography?
What Is Geography? Geography is the observe of the bodily functions of the earth, inclusive of how people have an effect on the earth and are tormented by it. Geography offers with bodily elements of the earth: the composition, …

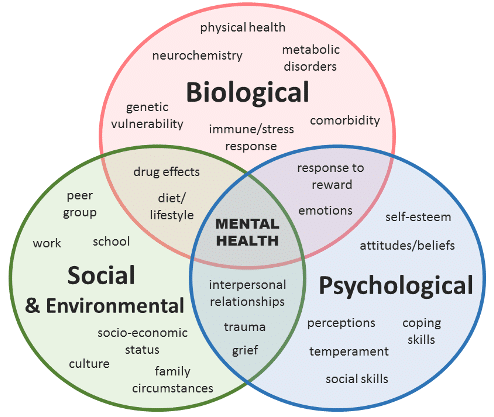
Biopsychosocial Assessment: Why the Biopsycho and Rarely the Social?
As a social employee concerned in imparting medical evaluation and intervention with kids and mother and father, I will define my worries over the accuracy of our use of the term “bio-psycho-social” to explain the content material of …

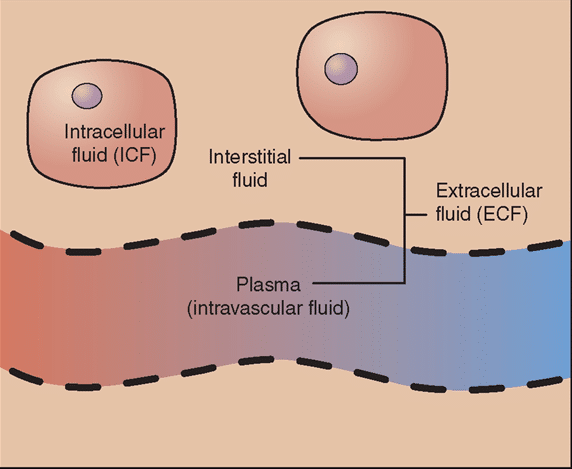
Intracellular Fluid: Definition & Composition
What is Intracellular Fluid? Human cells are bathed in fluids each within side the mobile and out. In fact, the water this is within side the mobile makes up approximately 42% of the entire frame weight. The fluid …


Horizontal Asymptotes: Definition & Rules
Definitions Before stepping into the definition of a horizontal asymptote, let’s first cross over what a feature is. A feature is an equation that tells you the way matters relate. Usually, features inform you how y is associated to x. Functions are regularly …
